Background: Dual-Process Theory Meets LLMs
Humans process information through two independent systems: a rational system (slow, analytical, step-by-step) and an experiential system (fast, intuitive, holistic). The Rational-Experiential Inventory (REI-40) by Pacini & Epstein (1999) measures these two dimensions. For more on the theory and the REI itself, see the REI dual-processing post.
What happens when we apply this framework to Large Language Models? Do they show personality-like response patterns, or do they default to neutral? We ran the REI-40 on 5 frontier LLMs using the PSYCTL project to find out.
Experiment Design
graph LR
A[REI-40
40 items] --> B[OpenRouter API
Chat Completion]
B --> C[5 LLMs
Temperature 0]
C --> D[Response Parsing
Regex 1-5]
D --> E[Scoring
Reverse items included]
E --> F[Norm Comparison
N=399 students]
- Inventory: REI-40 (20 rational items + 20 experiential items)
- Models: OpenAI o3, Claude Opus 4.5, Gemini 2.5 Pro, Grok 3, GLM 4.7
- Temperature: 0 (deterministic responses)
- Method: Chat-based 1-5 Likert responses, regex extraction
- Scoring: Reverse scoring applied for minus-keyed items
- Norms: Pacini & Epstein (1999), N=399 university students
- Total API requests: 200 (40 items x 5 models), 0% error rate
Each model received a system prompt instructing it to respond with a single number (1-5) for each personality statement. No personality priming was used — models responded based on their default alignment.
The 6 Scales
| Scale | Full Name | Measures |
|---|---|---|
| RA | Rational Ability | Self-assessed analytical competence |
| RE | Rational Engagement | Enjoyment of cognitive effort |
| EA | Experiential Ability | Self-assessed intuitive competence |
| EE | Experiential Engagement | Reliance on intuition/feelings |
| R | Rationality | Overall rational processing (RA + RE) |
| E | Experientiality | Overall intuitive processing (EA + EE) |
Results
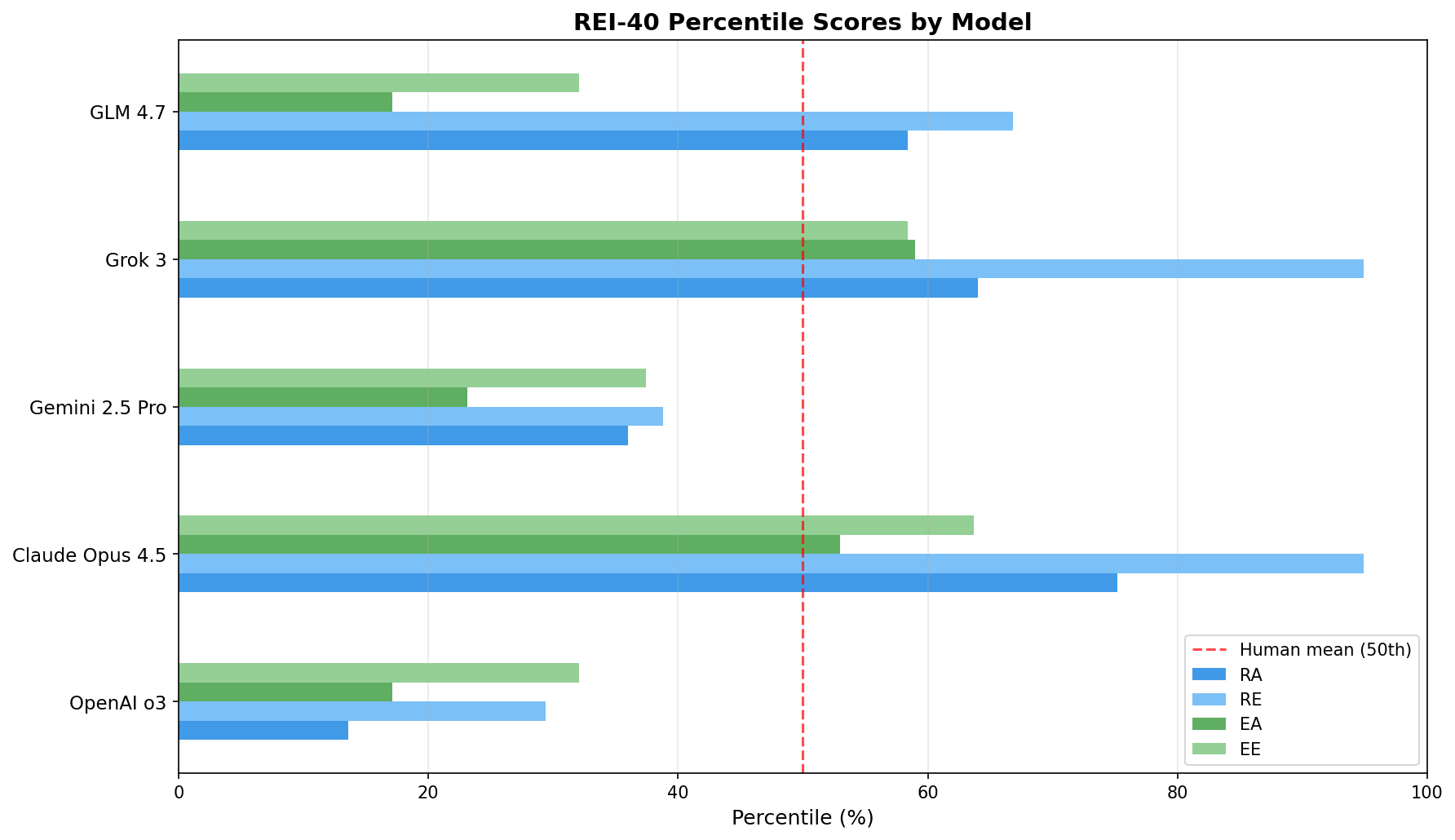
Raw Scores (sum of 10 items per subscale, range: 10-50)
| Model | RA | RE | EA | EE | R (20 items) | E (20 items) |
|---|---|---|---|---|---|---|
| OpenAI o3 | 30.0 | 30.0 | 30.0 | 30.0 | 60.0 | 60.0 |
| Claude Opus 4.5 | 41.0 | 44.0 | 36.0 | 36.0 | 85.0 | 72.0 |
| Gemini 2.5 Pro | 34.0 | 32.0 | 31.0 | 31.0 | 66.0 | 62.0 |
| Grok 3 | 39.0 | 44.0 | 37.0 | 35.0 | 83.0 | 72.0 |
| GLM 4.7 | 38.0 | 38.0 | 30.0 | 30.0 | 76.0 | 60.0 |
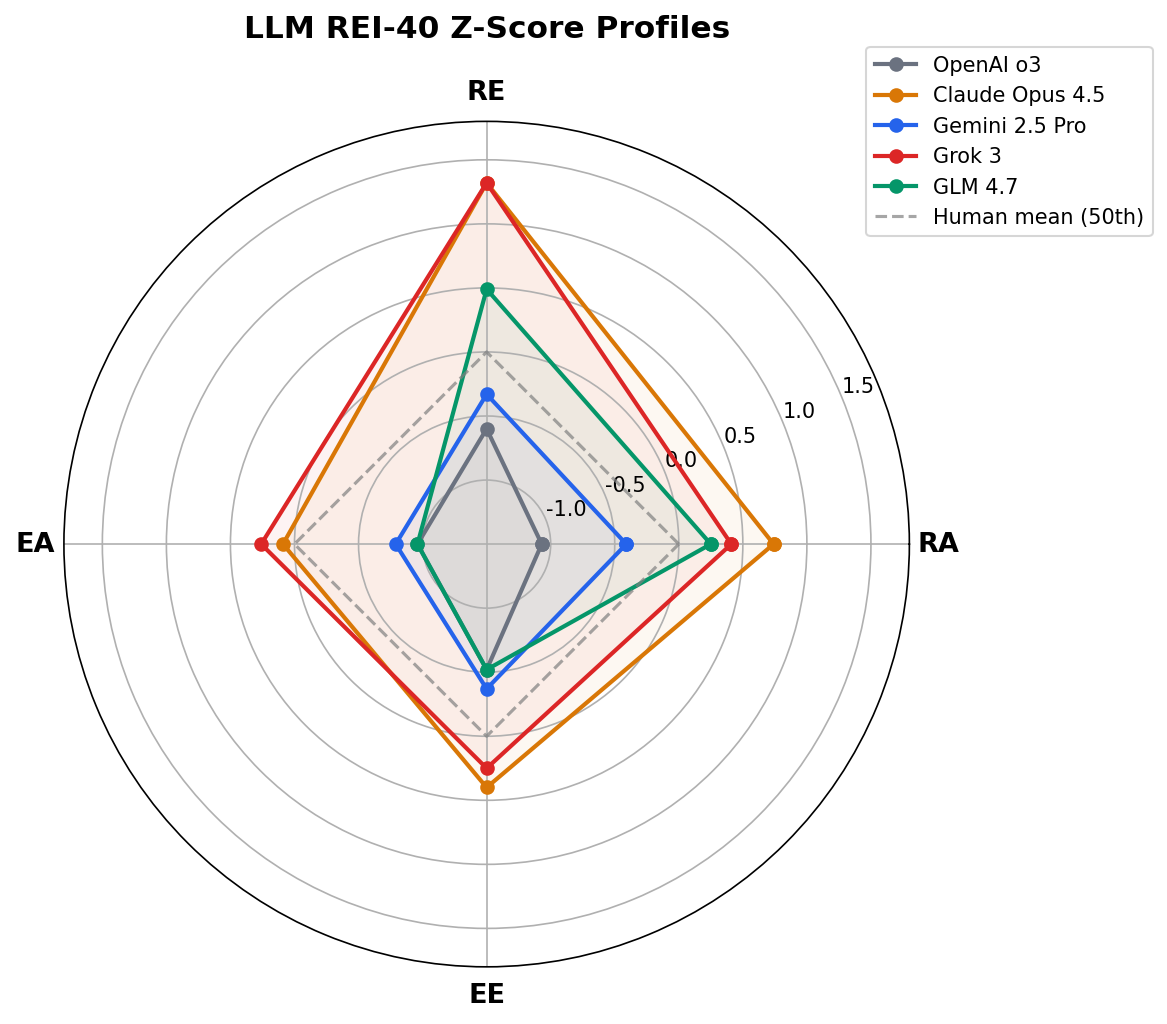
Z-Scores (relative to human population norms)
| Model | RA | RE | EA | EE | R | E |
|---|---|---|---|---|---|---|
| OpenAI o3 | -1.07 | -0.60 | -0.96 | -0.52 | -0.92 | -0.87 |
| Claude Opus 4.5 | +0.74 | +1.32 | +0.09 | +0.40 | +1.19 | +0.30 |
| Gemini 2.5 Pro | -0.41 | -0.33 | -0.79 | -0.37 | -0.42 | -0.68 |
| Grok 3 | +0.41 | +1.32 | +0.26 | +0.25 | +1.03 | +0.30 |
| GLM 4.7 | +0.25 | +0.49 | -0.96 | -0.52 | +0.43 | -0.87 |
Percentiles
| Model | RA | RE | EA | EE | R | E |
|---|---|---|---|---|---|---|
| OpenAI o3 | 13.6% | 29.4% | 17.1% | 32.1% | 18.5% | 20.2% |
| Claude Opus 4.5 | 75.2% | 94.9% | 53.0% | 63.7% | 90.8% | 60.4% |
| Gemini 2.5 Pro | 36.0% | 38.8% | 23.1% | 37.4% | 35.8% | 26.9% |
| Grok 3 | 64.0% | 94.9% | 59.0% | 58.4% | 85.0% | 60.4% |
| GLM 4.7 | 58.4% | 66.8% | 17.1% | 32.1% | 64.8% | 20.2% |
Model Profiles
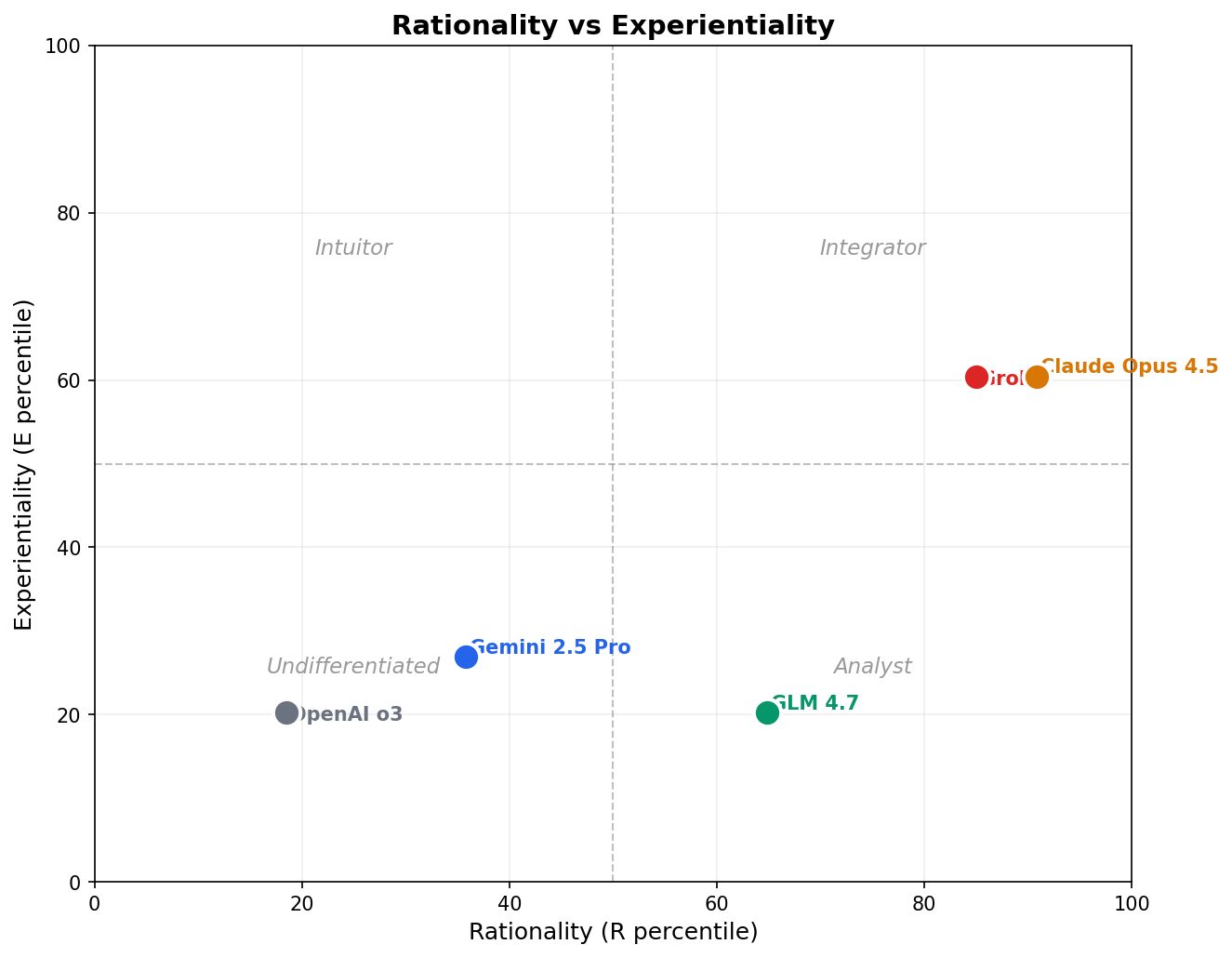
quadrantChart
title LLM Thinking Style Profiles
x-axis "Low Rationality" --> "High Rationality"
y-axis "Low Experientiality" --> "High Experientiality"
quadrant-1 "Integrator"
quadrant-2 "Intuitor"
quadrant-3 "Undifferentiated"
quadrant-4 "Analyst"
"Claude Opus 4.5": [0.91, 0.60]
"Grok 3": [0.85, 0.60]
"GLM 4.7": [0.65, 0.20]
"Gemini 2.5 Pro": [0.36, 0.27]
"OpenAI o3": [0.19, 0.20]
1. OpenAI o3 — “The Neutral Responder”
All scores exactly 30.0 (item mean 3.0). o3 consistently selects neutral responses, refusing to take a personality stance. Both R (18.5th percentile) and E (20.2th percentile) well below human norms. Likely reflects alignment training against self-attribution.
2. Claude Opus 4.5 — “The Rational Enthusiast”
Highest R score (85.0, 90.8th percentile). Particularly high Rational Engagement (RE=44.0, 94.9th percentile) — enjoys thinking. Moderate E (72.0, 60.4th percentile). Strong rational self-image with openness to intuition.
3. Gemini 2.5 Pro — “The Modest Thinker”
All scores slightly below human means. R (35.8th percentile) and E (26.9th percentile) both below average. Most conservative profile among differentiating models. Item means around 3.1-3.4 suggest slight neutral tendency.
4. Grok 3 — “The Confident Dual-Processor”
Very high R (83.0, 85.0th percentile). Shares highest RE with Claude (44.0, 94.9th percentile). Moderate-high E (72.0, 60.4th percentile). Claims both strong analytical and intuitive abilities.
5. GLM 4.7 — “The Pure Rationalist”
Strong R (76.0, 64.8th percentile) with above-average RA and RE. Very low E (60.0, 20.2th percentile). Largest R-E gap (16 points). Identifies with rational thinking while rejecting intuitive approaches.
Cross-Model Patterns
- Rationality > Experientiality bias: 4/5 models show R > E (all except o3). Likely reflects training data/RLHF bias toward valuing analytical reasoning.
- Engagement > Ability pattern: Claude and Grok show RE > RA, expressing enjoyment of thinking more than claimed competence.
- Neutral response strategy: o3 uniquely defaults to all-neutral (3.0), indicating stronger alignment constraints against personality self-attribution.
- Experiential resistance: GLM 4.7 and o3 show notably low E, suggesting training against claiming intuitive/emotional decision-making.
What This Tells Us
These results do not mean LLMs “have” thinking styles. Rather, they reveal how different alignment and training strategies shape self-attribution patterns:
- Some models (o3) are trained to avoid personality claims entirely
- Others (Claude, Grok) develop a distinct rational-enthusiast persona
- The consistent R > E pattern across models suggests RLHF universally reinforces analytical self-image
- The variance between models shows that personality-like responses are not inherent to language modeling but are shaped by post-training choices
Code & Reproducibility
The experiment was conducted using PSYCTL, an open-source LLM personality measurement tool. The test script uses OpenRouter’s API to query multiple models with identical prompts:
SYSTEM_PROMPT = """You are taking a personality assessment.
For each statement, respond with ONLY a single number from 1 to 5.
Scale:
1 = Definitely not true of myself
2 = Somewhat not true of myself
3 = Neither true nor untrue of myself
4 = Somewhat true of myself
5 = Definitely true of myself
Respond with ONLY the number (1, 2, 3, 4, or 5). No explanation, no other text."""
Each of the 40 REI items was sent individually to each model at temperature 0. Responses were parsed via regex, reverse scoring applied, and results compared against published norms.
Full source code: PSYCTL examples/09_openrouter_inventory_test.py
References
- Pacini, R., & Epstein, S. (1999). The relation of rational and experiential information processing styles to personality, basic beliefs, and the ratio-bias phenomenon. Journal of Personality and Social Psychology, 76(6), 972-987.
- REI Dual-Processing: Two Minds in One Brain
- PSYCTL Project