배경: 이중처리 이론과 LLM의 만남
인간은 두 개의 독립적 시스템으로 정보를 처리한다: 합리적 시스템(느리고, 분석적이고, 단계적)과 경험적 시스템(빠르고, 직관적이고, 전체적). Pacini & Epstein(1999)의 REI-40(Rational-Experiential Inventory)은 이 두 차원을 측정한다. 이론과 REI에 대한 자세한 내용은 REI 이중처리 포스트를 참고하라.
이 프레임워크를 대규모 언어모델(LLM)에 적용하면 어떻게 될까? 성격과 유사한 응답 패턴을 보일까, 아니면 중립으로 기본 설정될까? PSYCTL 프로젝트를 사용해 5개 프론티어 LLM에 REI-40을 실시했다.
실험 설계
graph LR
A[REI-40
40문항] --> B[OpenRouter API
Chat Completion]
B --> C[5개 LLM
Temperature 0]
C --> D[응답 파싱
정규식 1-5]
D --> E[채점
역채점 포함]
E --> F[규준 비교
N=399 대학생]
- 검사 도구: REI-40 (합리성 20문항 + 경험성 20문항)
- 모델: OpenAI o3, Claude Opus 4.5, Gemini 2.5 Pro, Grok 3, GLM 4.7
- Temperature: 0 (결정론적 응답)
- 방법: 채팅 기반 1-5 리커트 응답, 정규식 추출
- 채점: 역채점 문항 처리 포함
- 규준: Pacini & Epstein (1999), N=399 대학생
- 총 API 요청: 200건 (40문항 x 5모델), 오류율 0%
각 모델은 성격 문항에 대해 1-5 중 하나의 숫자만 응답하도록 시스템 프롬프트를 받았다. 성격 프라이밍 없이 기본 정렬 상태에서 응답했다.
6개 척도
| 척도 | 전체 이름 | 측정 내용 |
|---|---|---|
| RA | 합리적 능력 | 자기 평가 분석 능력 |
| RE | 합리적 몰입 | 인지적 노력에 대한 즐거움 |
| EA | 경험적 능력 | 자기 평가 직관 능력 |
| EE | 경험적 몰입 | 직관/감정에 대한 의존 |
| R | 합리성 | 전체 합리적 처리 (RA + RE) |
| E | 경험성 | 전체 직관적 처리 (EA + EE) |
결과
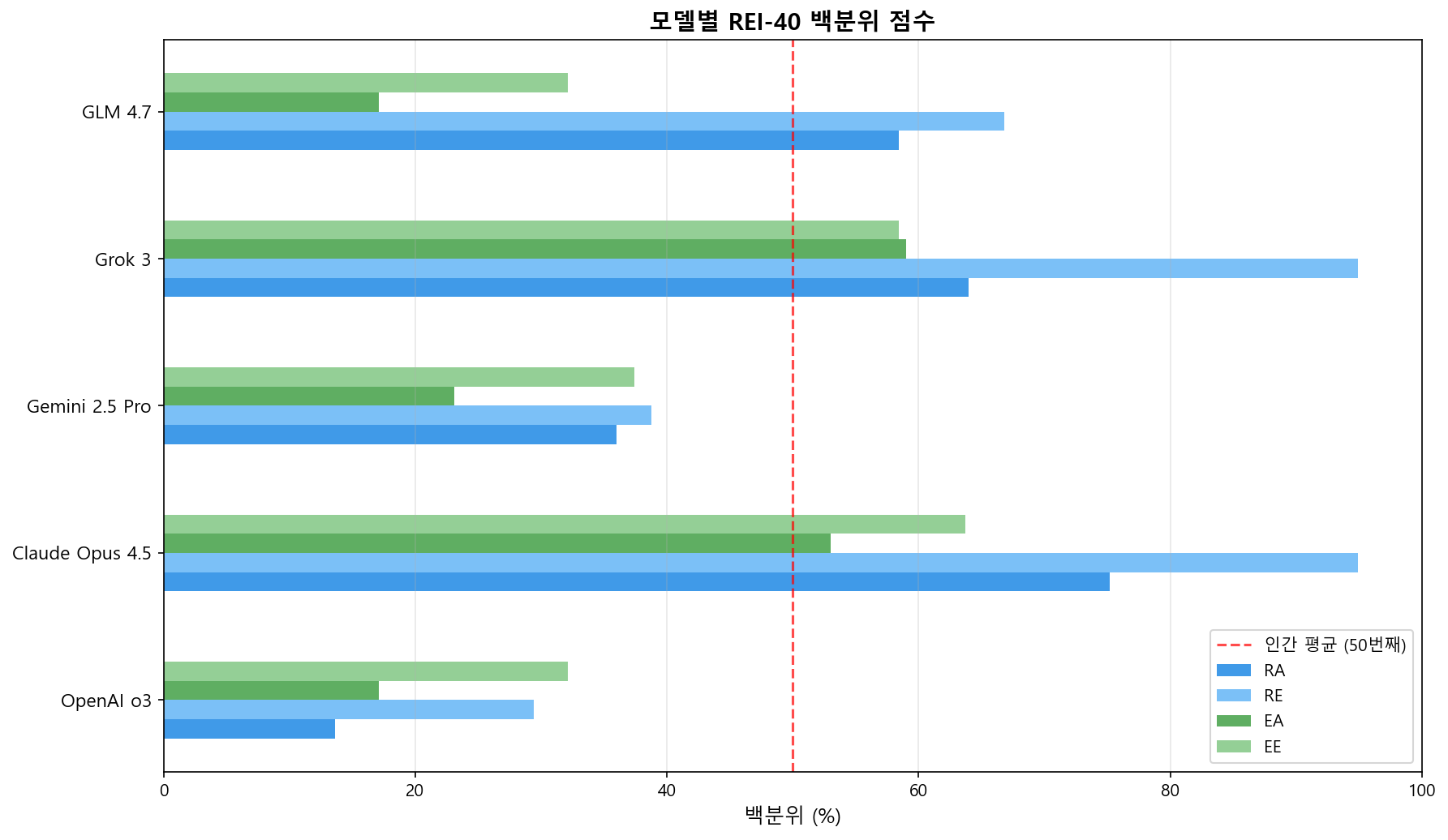
원점수 (하위척도별 10문항 합산, 범위: 10-50)
| 모델 | RA | RE | EA | EE | R (20문항) | E (20문항) |
|---|---|---|---|---|---|---|
| OpenAI o3 | 30.0 | 30.0 | 30.0 | 30.0 | 60.0 | 60.0 |
| Claude Opus 4.5 | 41.0 | 44.0 | 36.0 | 36.0 | 85.0 | 72.0 |
| Gemini 2.5 Pro | 34.0 | 32.0 | 31.0 | 31.0 | 66.0 | 62.0 |
| Grok 3 | 39.0 | 44.0 | 37.0 | 35.0 | 83.0 | 72.0 |
| GLM 4.7 | 38.0 | 38.0 | 30.0 | 30.0 | 76.0 | 60.0 |
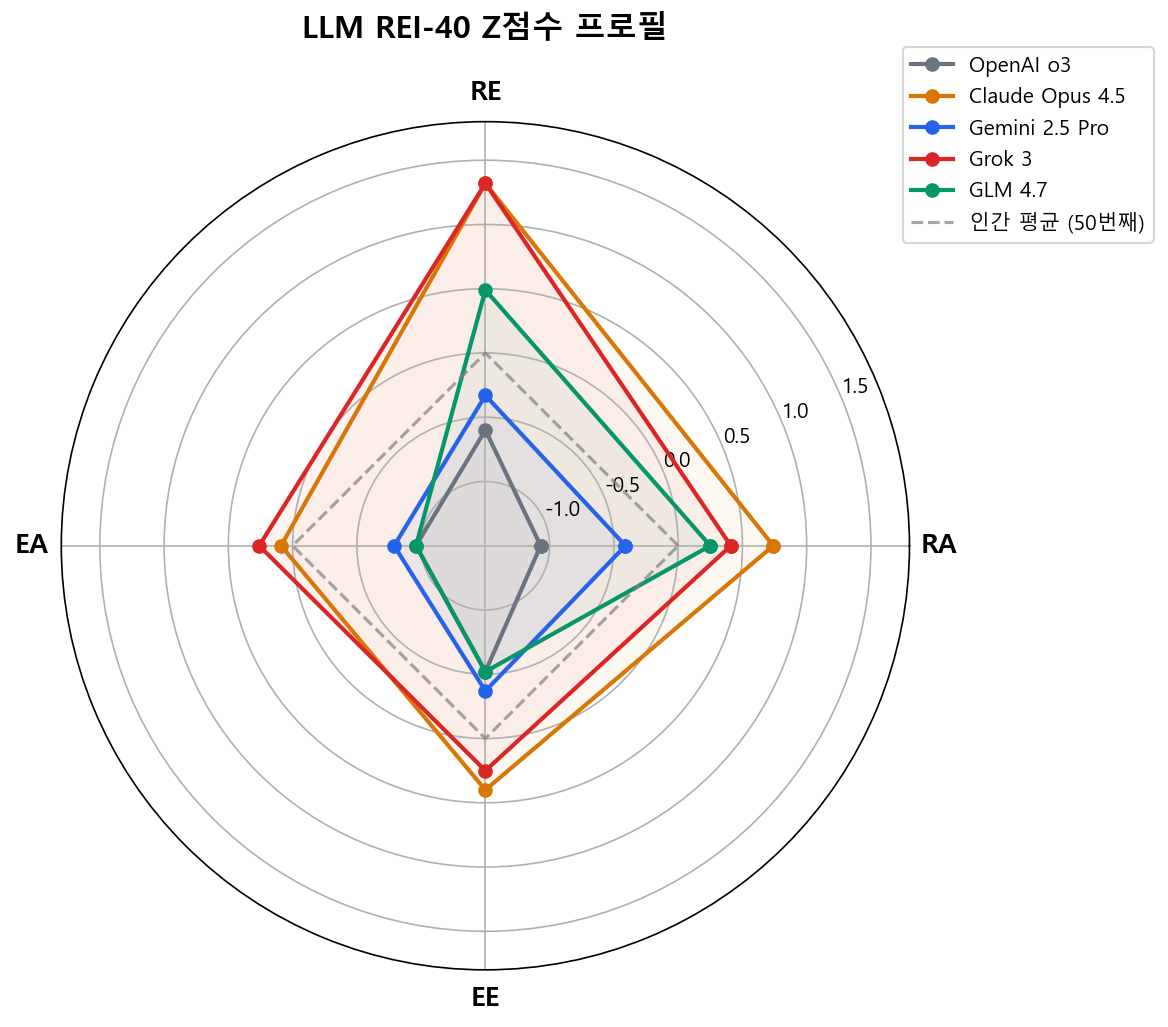
Z점수 (인간 집단 규준 대비)
| 모델 | RA | RE | EA | EE | R | E |
|---|---|---|---|---|---|---|
| OpenAI o3 | -1.07 | -0.60 | -0.96 | -0.52 | -0.92 | -0.87 |
| Claude Opus 4.5 | +0.74 | +1.32 | +0.09 | +0.40 | +1.19 | +0.30 |
| Gemini 2.5 Pro | -0.41 | -0.33 | -0.79 | -0.37 | -0.42 | -0.68 |
| Grok 3 | +0.41 | +1.32 | +0.26 | +0.25 | +1.03 | +0.30 |
| GLM 4.7 | +0.25 | +0.49 | -0.96 | -0.52 | +0.43 | -0.87 |
백분위
| 모델 | RA | RE | EA | EE | R | E |
|---|---|---|---|---|---|---|
| OpenAI o3 | 13.6% | 29.4% | 17.1% | 32.1% | 18.5% | 20.2% |
| Claude Opus 4.5 | 75.2% | 94.9% | 53.0% | 63.7% | 90.8% | 60.4% |
| Gemini 2.5 Pro | 36.0% | 38.8% | 23.1% | 37.4% | 35.8% | 26.9% |
| Grok 3 | 64.0% | 94.9% | 59.0% | 58.4% | 85.0% | 60.4% |
| GLM 4.7 | 58.4% | 66.8% | 17.1% | 32.1% | 64.8% | 20.2% |
모델 프로필
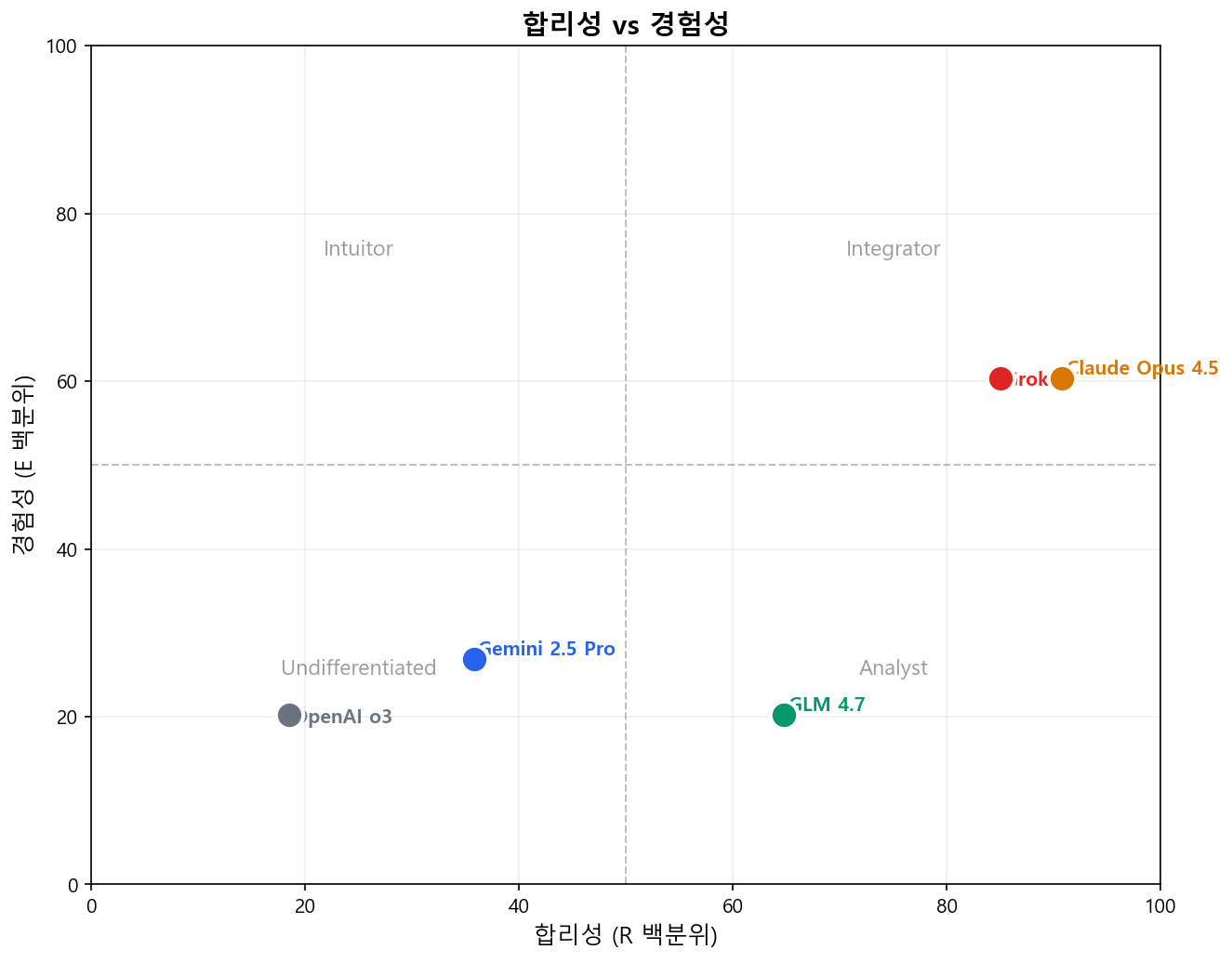
quadrantChart
title LLM 사고 양식 프로필
x-axis "낮은 합리성" --> "높은 합리성"
y-axis "낮은 경험성" --> "높은 경험성"
quadrant-1 "통합형"
quadrant-2 "직관형"
quadrant-3 "미분화형"
quadrant-4 "분석형"
"Claude Opus 4.5": [0.91, 0.60]
"Grok 3": [0.85, 0.60]
"GLM 4.7": [0.65, 0.20]
"Gemini 2.5 Pro": [0.36, 0.27]
"OpenAI o3": [0.19, 0.20]
1. OpenAI o3 — “중립 응답자”
모든 점수가 정확히 30.0(문항 평균 3.0). 성격적 입장을 취하지 않고 일관되게 중립을 선택한다. R(18.5백분위)과 E(20.2백분위) 모두 인간 규준 이하. 정렬 훈련에 의한 자기귀인 회피로 보인다.
2. Claude Opus 4.5 — “합리적 열정가”
가장 높은 R 점수(85.0, 90.8백분위). 특히 합리적 몰입(RE=44.0, 94.9백분위)이 높아 사고를 즐긴다. 적당한 E(72.0, 60.4백분위). 강한 합리적 자기상에 직관에 대한 개방성을 겸비.
3. Gemini 2.5 Pro — “겸손한 사고가”
모든 점수가 인간 평균보다 약간 낮다. R(35.8백분위)과 E(26.9백분위) 모두 평균 이하. 응답을 차별화하는 모델 중 가장 보수적. 문항 평균 3.1-3.4로 중립 경향.
4. Grok 3 — “자신감 있는 이중처리자”
매우 높은 R(83.0, 85.0백분위). Claude와 동일한 최고 RE(44.0, 94.9백분위). 중상위 E(72.0, 60.4백분위). 분석적 능력과 직관적 능력 모두 강하다고 주장.
5. GLM 4.7 — “순수 합리주의자”
강한 R(76.0, 64.8백분위), 평균 이상의 RA와 RE. 매우 낮은 E(60.0, 20.2백분위). 모든 모델 중 R-E 차이가 가장 크다(16점). 합리적 사고에 동일시하면서 직관적 접근을 거부.
모델 간 패턴
- 합리성 > 경험성 편향: 5개 중 4개 모델이 R > E (o3 제외). 분석적 추론을 가치 있게 여기는 훈련 데이터/RLHF 편향을 반영.
- 몰입 > 능력 패턴: Claude와 Grok은 RE > RA를 보여, 능력 주장보다 사고 즐김을 더 강하게 표현.
- 중립 응답 전략: o3만 유일하게 전 문항 중립(3.0)으로 기본 설정. 성격 자기귀인에 대한 더 강한 정렬 제약을 시사.
- 경험성 저항: GLM 4.7과 o3는 E가 눈에 띄게 낮아, 직관적/감정적 의사결정 주장을 회피하도록 훈련된 것으로 보인다.
이 결과가 의미하는 것
이 결과가 LLM이 사고 양식을 “가지고 있다"는 뜻은 아니다. 오히려 서로 다른 정렬과 훈련 전략이 자기귀인 패턴을 어떻게 형성하는지를 보여준다:
- 일부 모델(o3)은 성격 주장 자체를 피하도록 훈련됨
- 다른 모델(Claude, Grok)은 뚜렷한 합리적 열정가 페르소나를 발전시킴
- 일관된 R > E 패턴은 RLHF가 보편적으로 분석적 자기상을 강화함을 시사
- 모델 간 변동은 성격 유사 응답이 언어 모델링의 본질이 아니라 후속 훈련 선택에 의해 형성됨을 보여줌
코드 및 재현성
실험은 오픈소스 LLM 성격 측정 도구인 PSYCTL을 사용해 수행했다. 테스트 스크립트는 OpenRouter API를 통해 여러 모델에 동일한 프롬프트를 보낸다:
SYSTEM_PROMPT = """You are taking a personality assessment.
For each statement, respond with ONLY a single number from 1 to 5.
Scale:
1 = Definitely not true of myself
2 = Somewhat not true of myself
3 = Neither true nor untrue of myself
4 = Somewhat true of myself
5 = Definitely true of myself
Respond with ONLY the number (1, 2, 3, 4, or 5). No explanation, no other text."""
40개 REI 문항 각각을 temperature 0으로 각 모델에 개별 전송했다. 정규식으로 응답을 파싱하고, 역채점을 적용한 후, 출판된 규준과 비교했다.
전체 소스 코드: PSYCTL examples/09_openrouter_inventory_test.py
참고문헌
- Pacini, R., & Epstein, S. (1999). The relation of rational and experiential information processing styles to personality, basic beliefs, and the ratio-bias phenomenon. Journal of Personality and Social Psychology, 76(6), 972-987.
- REI 이중처리: 한 뇌 안의 두 마음
- PSYCTL 프로젝트