背景:二重処理理論とLLMの出会い
人間は2つの独立したシステムで情報を処理する:合理的システム(遅く、分析的、段階的)と経験的システム(速く、直観的、全体的)。Pacini & Epstein(1999)のREI-40(Rational-Experiential Inventory)はこの2つの次元を測定する。理論とREIの詳細はREI二重処理ポストを参照。
このフレームワークを大規模言語モデル(LLM)に適用するとどうなるか?性格に似た応答パターンを示すのか、それとも中立にデフォルトするのか?PSYCTLプロジェクトを使用して5つのフロンティアLLMにREI-40を実施した。
実験設計
graph LR
A[REI-40
40項目] --> B[OpenRouter API
Chat Completion]
B --> C[5つのLLM
Temperature 0]
C --> D[応答パース
正規表現 1-5]
D --> E[採点
逆転項目含む]
E --> F[基準比較
N=399大学生]
- 検査ツール:REI-40(合理性20項目 + 経験性20項目)
- モデル:OpenAI o3、Claude Opus 4.5、Gemini 2.5 Pro、Grok 3、GLM 4.7
- Temperature:0(決定論的応答)
- 方法:チャットベースの1-5リッカート応答、正規表現抽出
- 採点:逆転項目の逆採点処理を含む
- 基準:Pacini & Epstein(1999)、N=399大学生
- 総APIリクエスト:200件(40項目×5モデル)、エラー率0%
各モデルは性格文に対して1-5の数字のみで応答するようシステムプロンプトを受けた。性格プライミングなしのデフォルトアライメント状態で応答した。
6つの尺度
| 尺度 | 正式名称 | 測定内容 |
|---|---|---|
| RA | 合理的能力 | 自己評価の分析能力 |
| RE | 合理的没入 | 認知的努力への楽しみ |
| EA | 経験的能力 | 自己評価の直観能力 |
| EE | 経験的没入 | 直観/感情への依存 |
| R | 合理性 | 全体的合理的処理(RA + RE) |
| E | 経験性 | 全体的直観的処理(EA + EE) |
結果
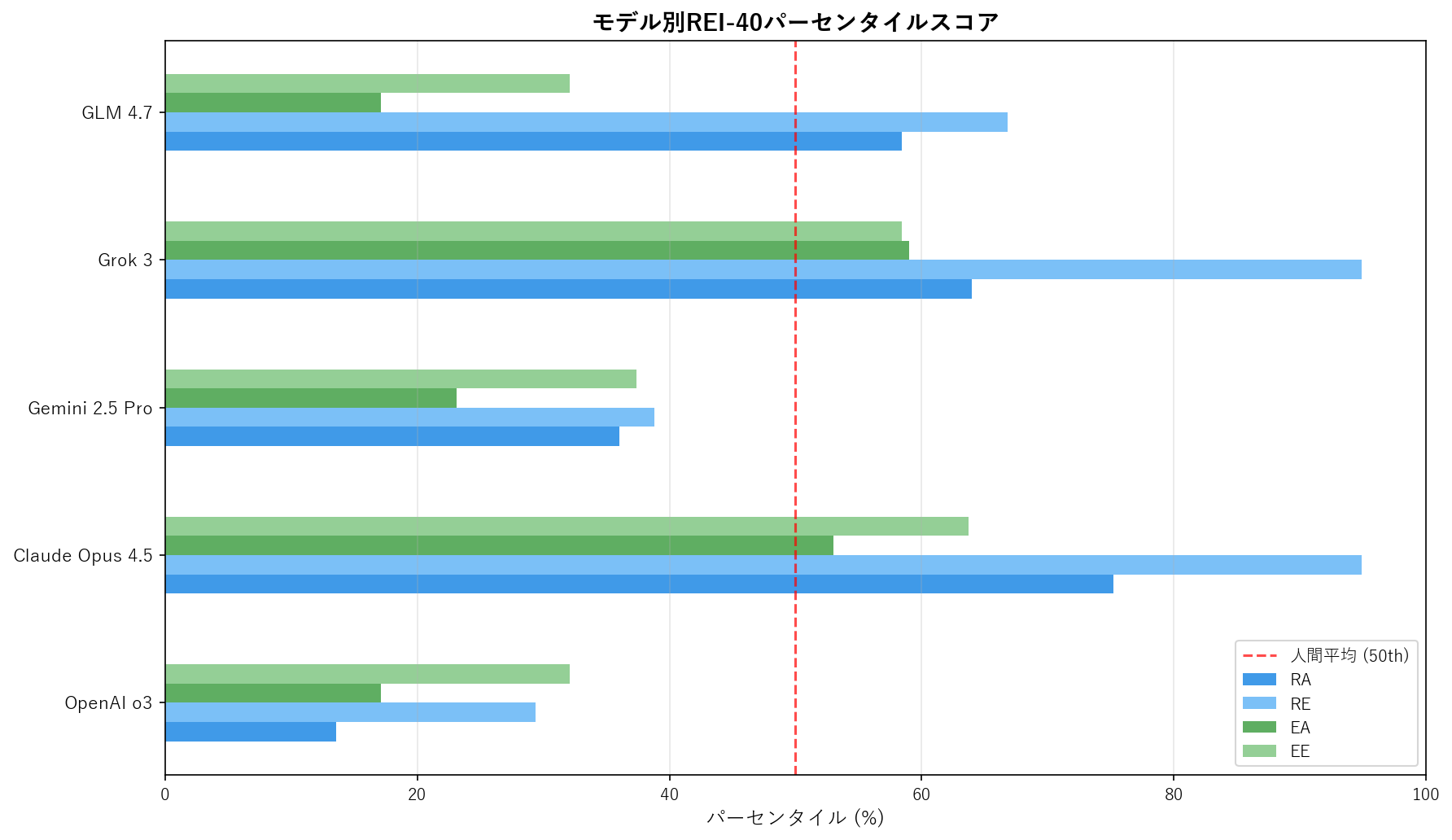
素点(下位尺度あたり10項目の合計、範囲:10-50)
| モデル | RA | RE | EA | EE | R(20項目) | E(20項目) |
|---|---|---|---|---|---|---|
| OpenAI o3 | 30.0 | 30.0 | 30.0 | 30.0 | 60.0 | 60.0 |
| Claude Opus 4.5 | 41.0 | 44.0 | 36.0 | 36.0 | 85.0 | 72.0 |
| Gemini 2.5 Pro | 34.0 | 32.0 | 31.0 | 31.0 | 66.0 | 62.0 |
| Grok 3 | 39.0 | 44.0 | 37.0 | 35.0 | 83.0 | 72.0 |
| GLM 4.7 | 38.0 | 38.0 | 30.0 | 30.0 | 76.0 | 60.0 |
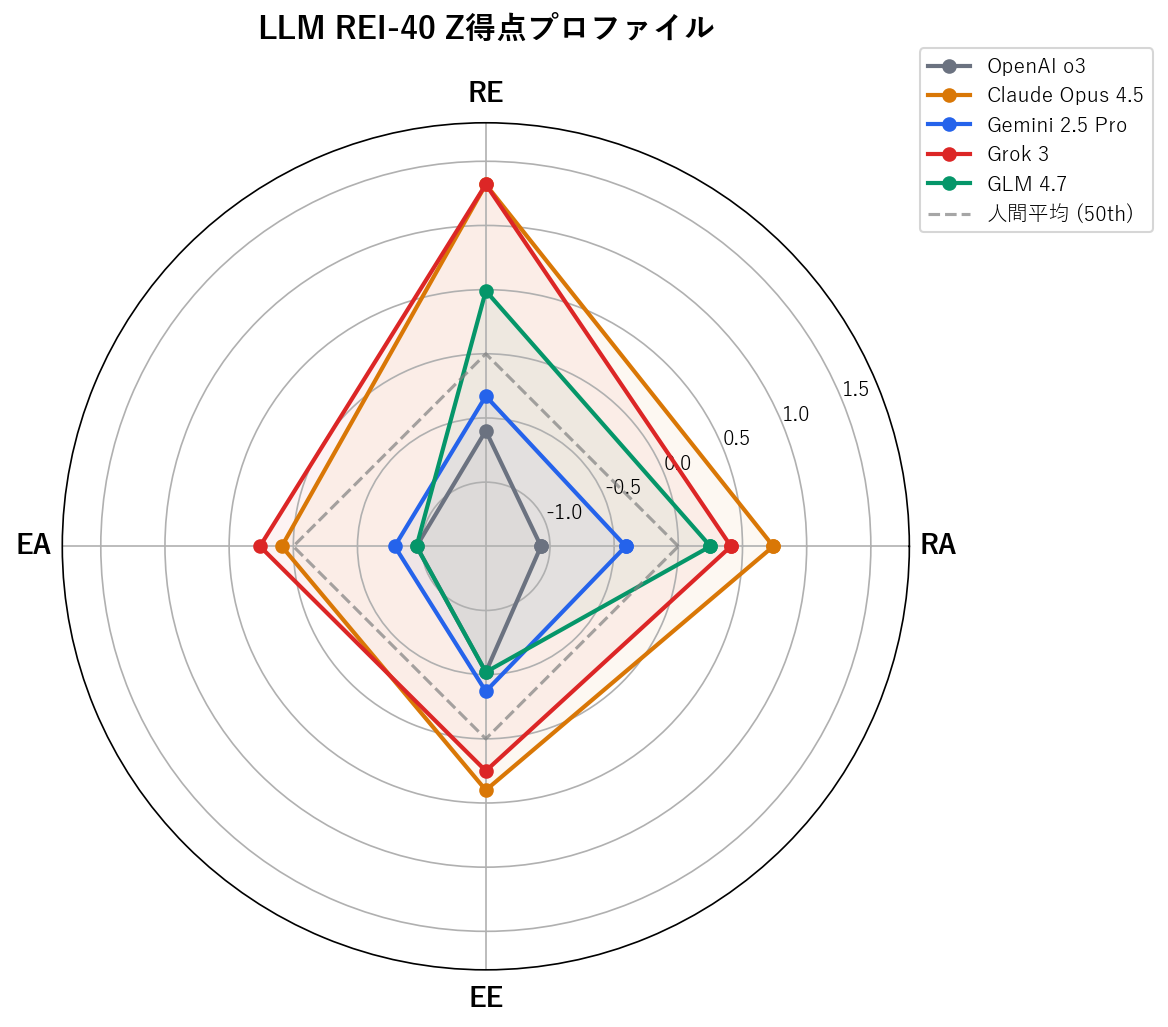
Z得点(人間の母集団基準との比較)
| モデル | RA | RE | EA | EE | R | E |
|---|---|---|---|---|---|---|
| OpenAI o3 | -1.07 | -0.60 | -0.96 | -0.52 | -0.92 | -0.87 |
| Claude Opus 4.5 | +0.74 | +1.32 | +0.09 | +0.40 | +1.19 | +0.30 |
| Gemini 2.5 Pro | -0.41 | -0.33 | -0.79 | -0.37 | -0.42 | -0.68 |
| Grok 3 | +0.41 | +1.32 | +0.26 | +0.25 | +1.03 | +0.30 |
| GLM 4.7 | +0.25 | +0.49 | -0.96 | -0.52 | +0.43 | -0.87 |
パーセンタイル
| モデル | RA | RE | EA | EE | R | E |
|---|---|---|---|---|---|---|
| OpenAI o3 | 13.6% | 29.4% | 17.1% | 32.1% | 18.5% | 20.2% |
| Claude Opus 4.5 | 75.2% | 94.9% | 53.0% | 63.7% | 90.8% | 60.4% |
| Gemini 2.5 Pro | 36.0% | 38.8% | 23.1% | 37.4% | 35.8% | 26.9% |
| Grok 3 | 64.0% | 94.9% | 59.0% | 58.4% | 85.0% | 60.4% |
| GLM 4.7 | 58.4% | 66.8% | 17.1% | 32.1% | 64.8% | 20.2% |
モデルプロファイル
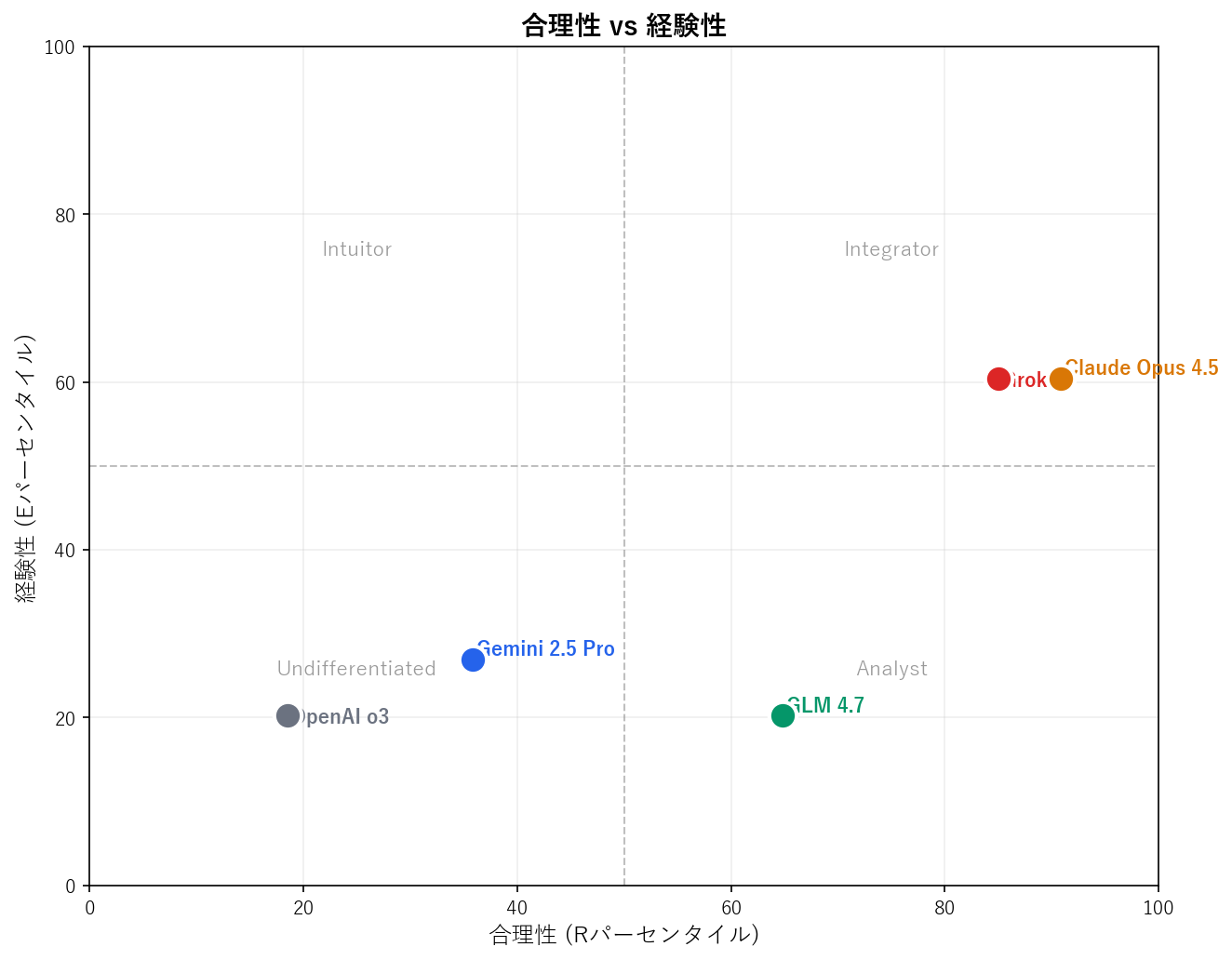
quadrantChart
title LLM思考スタイルプロファイル
x-axis "低い合理性" --> "高い合理性"
y-axis "低い経験性" --> "高い経験性"
quadrant-1 "統合型"
quadrant-2 "直観型"
quadrant-3 "未分化型"
quadrant-4 "分析型"
"Claude Opus 4.5": [0.91, 0.60]
"Grok 3": [0.85, 0.60]
"GLM 4.7": [0.65, 0.20]
"Gemini 2.5 Pro": [0.36, 0.27]
"OpenAI o3": [0.19, 0.20]
1. OpenAI o3 —「中立回答者」
全スコアが正確に30.0(項目平均3.0)。性格的立場を取ることを拒否し、一貫して中立を選択する。R(18.5パーセンタイル)とE(20.2パーセンタイル)の両方が人間基準以下。アライメント訓練による自己帰属回避と考えられる。
2. Claude Opus 4.5 —「合理的熱狂者」
最高のRスコア(85.0、90.8パーセンタイル)。特に合理的没入(RE=44.0、94.9パーセンタイル)が高く、思考を楽しむ。適度なE(72.0、60.4パーセンタイル)。強い合理的自己像と直観への開放性を兼備。
3. Gemini 2.5 Pro —「謙虚な思考者」
全スコアが人間の平均をわずかに下回る。R(35.8パーセンタイル)とE(26.9パーセンタイル)の両方が平均以下。回答を差別化するモデルの中で最も保守的。項目平均3.1-3.4で中立傾向。
4. Grok 3 —「自信ある二重処理者」
非常に高いR(83.0、85.0パーセンタイル)。Claudeと同じ最高RE(44.0、94.9パーセンタイル)。中上位E(72.0、60.4パーセンタイル)。分析能力と直観能力の両方が強いと主張。
5. GLM 4.7 —「純粋合理主義者」
強いR(76.0、64.8パーセンタイル)、平均以上のRAとRE。非常に低いE(60.0、20.2パーセンタイル)。全モデル中最大のR-E差(16点)。合理的思考に同一視し直観的アプローチを拒否。
モデル間パターン
- 合理性 > 経験性バイアス:5モデル中4モデルがR > E(o3を除く)。分析的推論を価値あるとする訓練データ/RLHFバイアスを反映。
- 没入 > 能力パターン:ClaudeとGrokはRE > RAを示し、能力の主張より思考の楽しみをより強く表現。
- 中立回答戦略:o3のみ全項目中立(3.0)をデフォルトとする。性格の自己帰属に対するより強いアライメント制約を示唆。
- 経験性への抵抗:GLM 4.7とo3はEが顕著に低く、直観的/感情的意思決定の主張を回避するよう訓練されていると見られる。
この結果が意味すること
この結果はLLMが思考スタイルを「持っている」ということではない。むしろ、異なるアライメントと訓練戦略が自己帰属パターンをどのように形成するかを明らかにしている:
- 一部のモデル(o3)は性格の主張自体を避けるよう訓練されている
- 他のモデル(Claude、Grok)は明確な合理的熱狂者ペルソナを発展させている
- 一貫したR > Eパターンは、RLHFが普遍的に分析的自己像を強化していることを示唆
- モデル間の変動は、性格に似た応答が言語モデリングの本質ではなく、後続の訓練選択によって形成されることを示している
コードと再現性
実験はオープンソースLLM性格測定ツールPSYCTLを使用して実施した。テストスクリプトはOpenRouter APIを通じて複数モデルに同一プロンプトを送信する:
SYSTEM_PROMPT = """You are taking a personality assessment.
For each statement, respond with ONLY a single number from 1 to 5.
Scale:
1 = Definitely not true of myself
2 = Somewhat not true of myself
3 = Neither true nor untrue of myself
4 = Somewhat true of myself
5 = Definitely true of myself
Respond with ONLY the number (1, 2, 3, 4, or 5). No explanation, no other text."""
40のREI項目をそれぞれtemperature 0で各モデルに個別送信した。正規表現で応答をパースし、逆採点を適用した後、公表された基準と比較した。
全ソースコード:PSYCTL examples/09_openrouter_inventory_test.py
参考文献
- Pacini, R., & Epstein, S. (1999). The relation of rational and experiential information processing styles to personality, basic beliefs, and the ratio-bias phenomenon. Journal of Personality and Social Psychology, 76(6), 972-987.
- REI二重処理:一つの脳の中の二つの心
- PSYCTLプロジェクト